Notes on Kleppmann SQL Transactions Talk
Updated Wed 2025-10-08 | 758 words
"Transactions: myths, surprises and opportunities" by Martin Kleppmann - YouTube
This talk is REALLY GOOD. Taking some notes...
3m - ACID - not a great acronym and the meaning has changed over time
3m50s - Durability data is fsync'd to disk and/or replicated
4m30s - Consistency - transactions move db from one consistent state to another - integrity constraints, etc. Vaguely defined. Rest of the talk.
6m30s - Atomicity - not concurrency. how faults are handled. you get either ALL or NONE of the writes in the transaction. A better name would be "Abortability"
8m20s - Transactions - multi-object atomicity. Rollback writes on abort
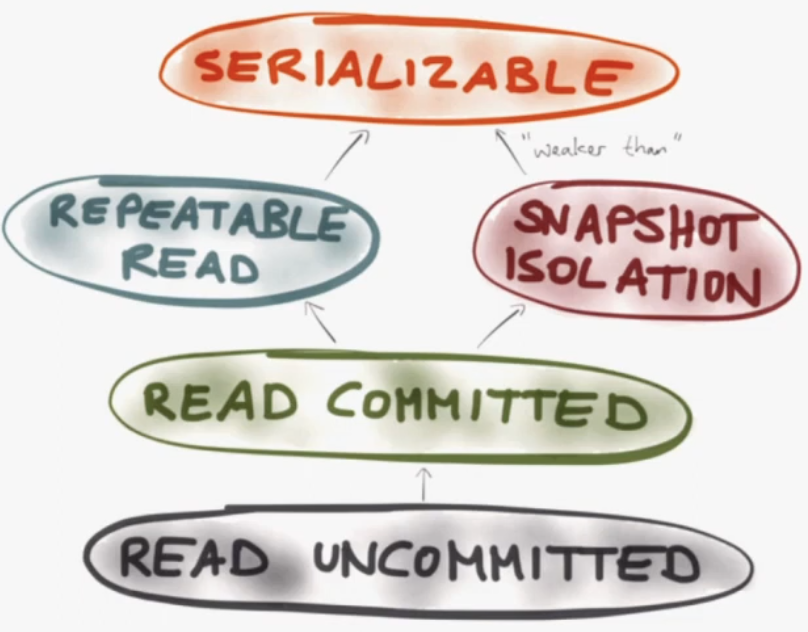
9m50s - Isolation - different types. "Serializability" means all transactions act THE SAME as if they were executing on a single thread. This is the rest of the talk!
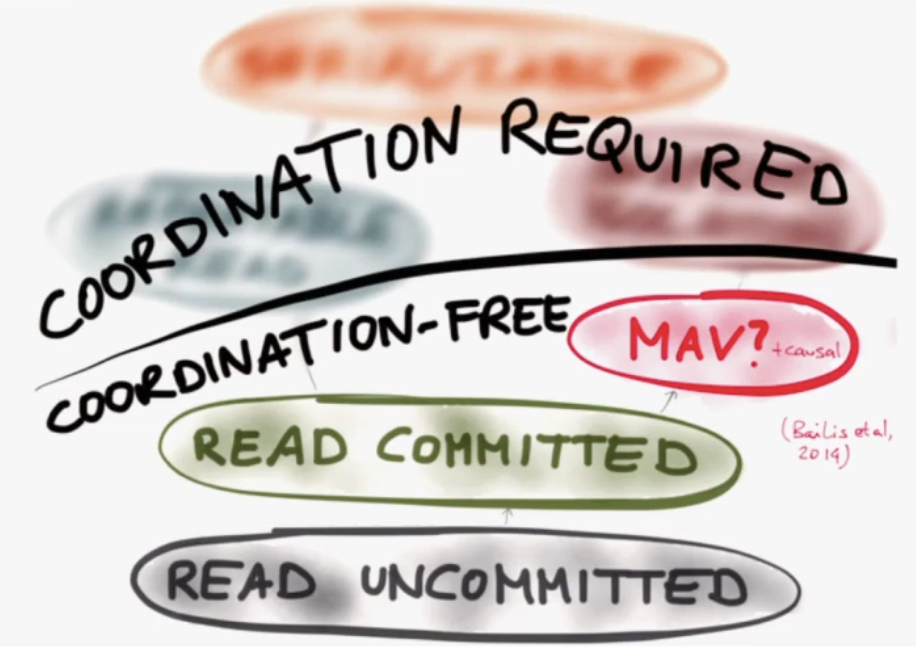
13m - race conditions at isolation levels. The rest of the talk talks about different errors and how moving "up" an isolation level prevents the error
13m10s - Read committed - default in Postgres, Oracle, SQL server
Prevents dirty reads and dirty writes
Dirty reads - one transaction reads data that another transaction has not yet committed
13m51s - Dirty writes

If you have two transactions, A and B, and they both want to write their names to values x and y at the same time, the end result should be x=A,y=A or x=B,y=B . a mix of names is called a dirty write.

Read committed prevents this.
15m - Read skew can occur unde READ COMMITTED
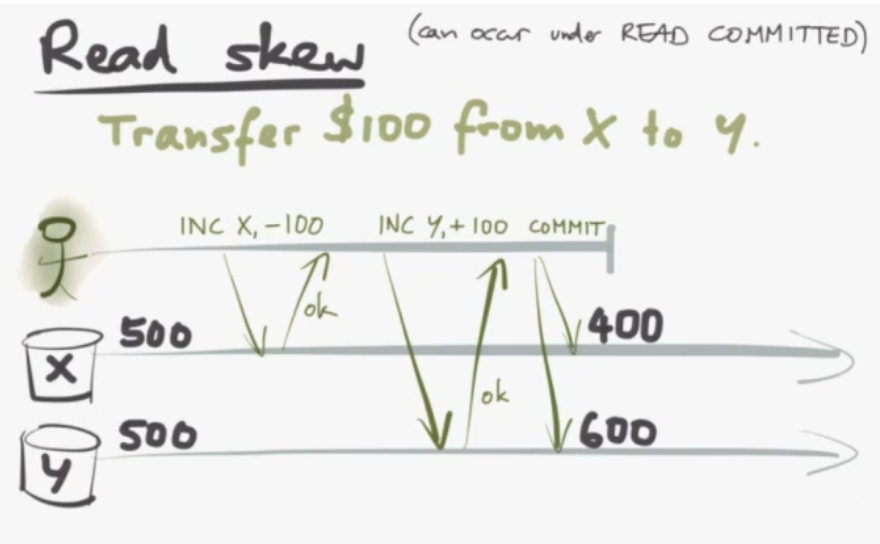
If you have two accounts with balances of 500 each, and you start a transaction to transfer 100 from X to Y
X = X - 100
Y + Y = 10016m - If another transaction reads X after the first operation, and Y after the second operation, they only see $900 total...
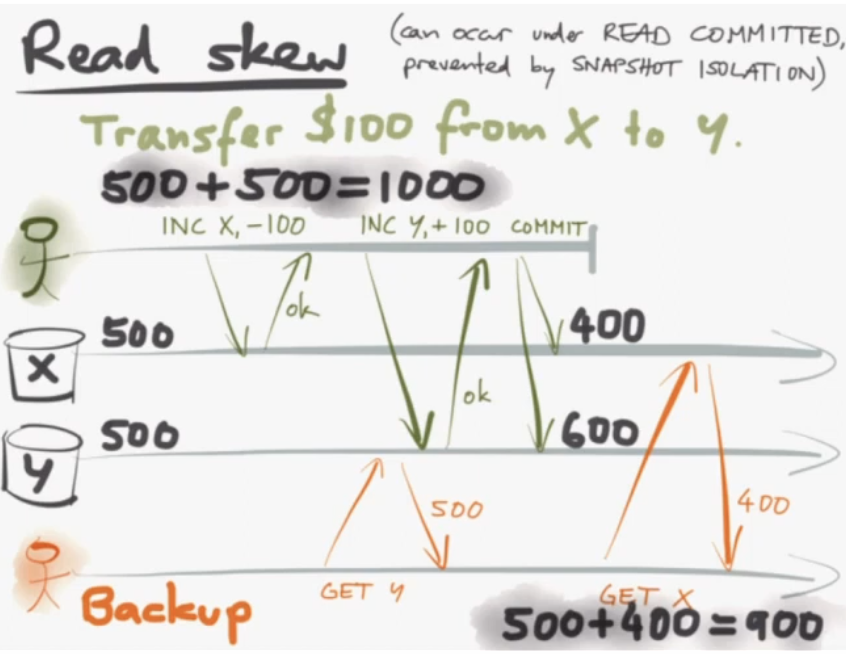
16m50s- The backup sees different parts of the database at different points in time. Occurs under READ COMMITTED isolation.
To prevent read skew, can use REPEATABLE READ or SNAPSHOT ISOLATION. Similar from users point of view but different from implementation level.
17m10s - REPEATABLE READ - locking.
17m30s - Snapshot isolation/ MVCC - Postgres and MySQL calls this "REPEATABLE READ"
A snapshot sees the database at one point in time. MVCC (Multi-version concurrency control) keeps different versions of data and presents transactions with the version appropriate to its time.
18m40s - What's the difference between snapshot and serializable?
Imagine a doctor oncall system. the constraint is there must be at least one doctor oncall, but doctors can swap oncalls. A swap looks like this
19m36s - doctor swap transaction

20m10s - even under snapshot isolation, we ended up with a database where the "must be at least one doctor oncall" constraint failed
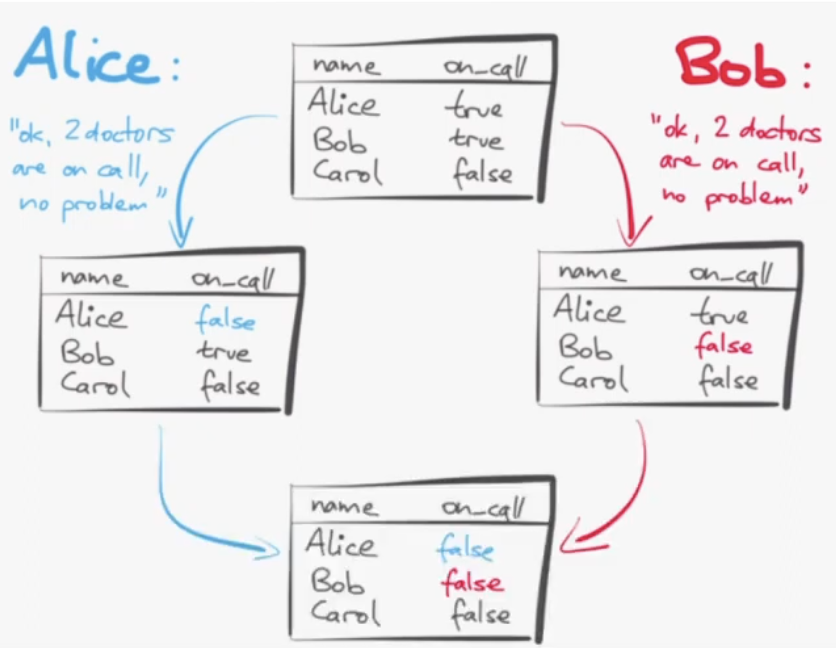
20m32s - This is because they both start with the same snapshot (where the constraint works), but update DIFFERENT values to fail the constraint.

This is prevented by SERIALIZABLE isolation
21m50s - SERIALIZABLE implementation strategies
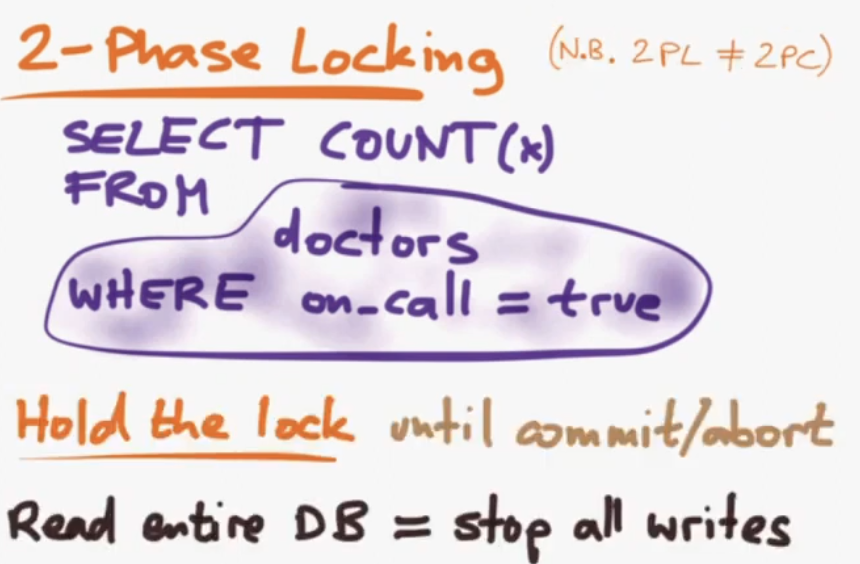
2-Phase Locking (not the same as 2-Phase Commit) . Take a shared lock on all of the stuff that you've read. Hold that lock until the end of the transaction. Super slow, especially if a transaction reads all the rows - locks all the rows
23m30s - BoldDB (I think) implementation strategy - Literally serialize transactions. Only feasible if transaction is fast (ideally )

25m40s - Serializable Snapshot Isolation. detect conflicts and abort. Postgres
Implement locks like 2PL, but don't block. "this write from this transaction conflicts with this read transaction". Try to resolve this at commit time.
28m - end of db isolation levels, Moving on to what transactions might mean for distributed systems
29m50s - Serializable transactions across services require slow protocols such as 2PC, 3PC.
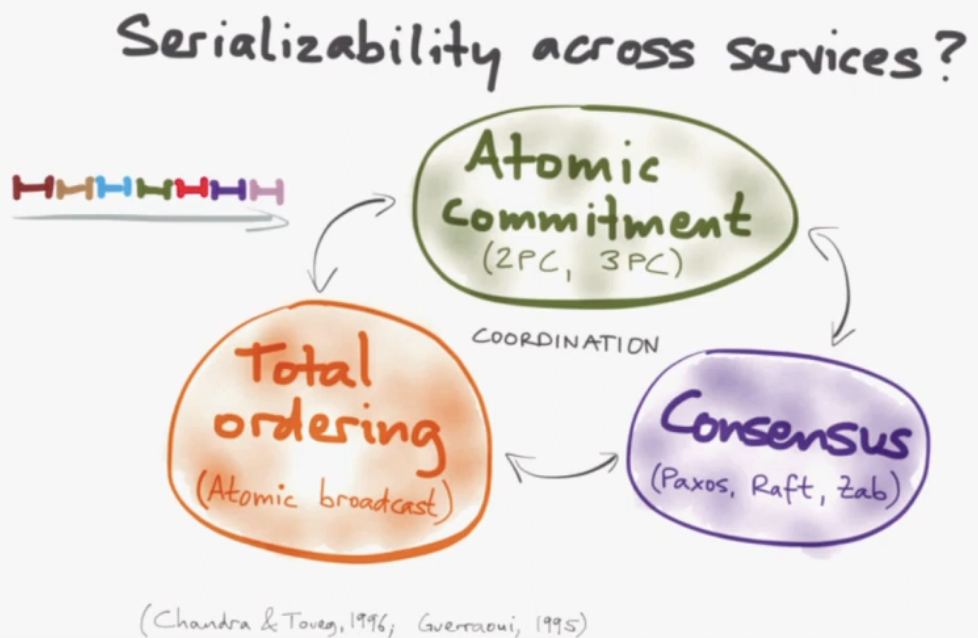
32m30s - Alternatives to serializability
Compensating transactions ( abort/rollback at application level). Saga pattern. Requires detecting and fixing constraint violations after the fact (apologizing to customers for selling them something that was sold out)
35m - compensating transactions are kind of like Atomicity and apologies are kind of like Consistency
36m - user issues with implicit relationships (posting message to unfriended friend)
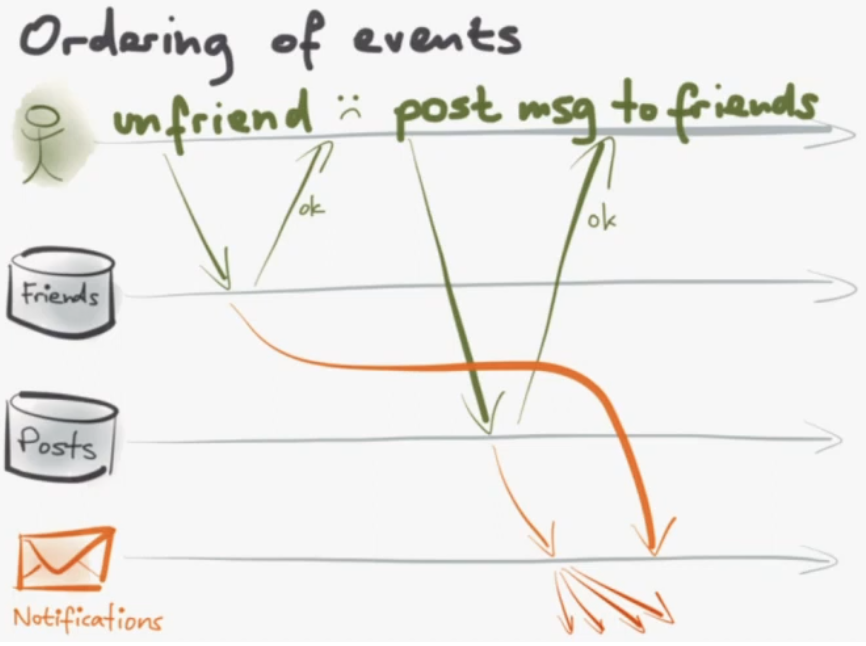
37m30s - Can we do better than eventual consistency?
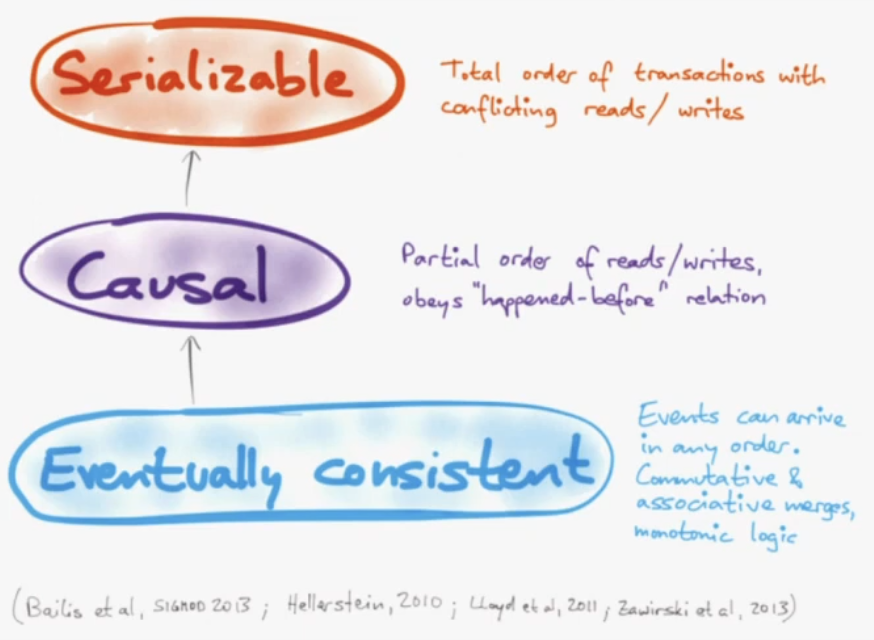
Probably can't do serializability - too slow. "Causality" can be maintained without global coordination. "Consistent snapshot". Can we make causality effiecient?